-
[JPA] @ElementCollection을 이용해서 Embeddable 타입의 Collection을 영속화스프링프레임워크/jpa 2021. 1. 29. 15:28
Embeddable 타입의 Collection
- 엔티티 클래스에서 Embeddable 타입의 Collection은 @ElementCollection을 사용해서 영속화 할 수 있습니다.
- Collection에 해당하는 클래스에는 @Embeddable 어노테이션을 반드시 붙여야 합니다.
- 엔티티 클래스와 Embeddable 타입의 클래스는 둘 사이를 매핑하는 새로운 테이블을 생성합니다.
- 해당 매핑 테이블에는 엔티티 클래스의 primary-key와 연결 된 foreign-key를 가지고 있습니다.
- 해당 매핑 테이블의 필드는 엔티티 클래스에 대한 foreign-key와 Embeddable 클래스의 필드들로 구성되어집니다.
- OneToMany와 유사하지만 대상이 Embeddable 클래스란 것이 다르다.
테스트를 위한 Entity 및 관련 클래스 작성
@NoArgsConstructor(access = AccessLevel.PROTECTED) @Getter @Entity public class Customer { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; private String name; @ElementCollection private List<PhoneNumber> phoneNumbers = new ArrayList<>(); public Customer(String name, PhoneNumber... phoneNumbers) { this.name = name; for (PhoneNumber phoneNumber : phoneNumbers) { this.phoneNumbers.add(phoneNumber); } } }@Getter @NoArgsConstructor @Embeddable public class PhoneNumber { private String phoneNumber; @Enumerated(EnumType.STRING) private PhoneType type; public PhoneNumber(String phoneNumber, PhoneType type) { this.phoneNumber = phoneNumber; this.type = type; } }public enum PhoneType { House, Work, Cell }public interface CustomerRepository extends JpaRepository<Customer, Long> { }엔티티에 의해서 생성되어지는 테이블의 구조는 아래와 같습니다.
customer 테이블
CREATE TABLE `customer` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;customer_phone_numbers 테이블 (매핑 테이블)
CREATE TABLE `customer_phone_numbers` ( `customer_id` bigint(20) NOT NULL, `phone_number` varchar(255) DEFAULT NULL, `type` varchar(255) DEFAULT NULL, KEY `FK8t59yk70tp1u41ltrlfkmk4ut` (`customer_id`), CONSTRAINT `FK8t59yk70tp1u41ltrlfkmk4ut` FOREIGN KEY (`customer_id`) REFERENCES `customer` (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;테스트 케이스 작성
우선 Customer를 등록 시 실행되는 SQL을 살펴보겠습니다.
- customer 테이블에 1개의 row 저장
- customer_phone_numbers 테이블에 2개의 row 저장
- Collection의 개수만큼 자동으로 INSERT
@Test @Order(1) public void 고객등록() { Customer customer = new Customer("장지현", new PhoneNumber("0317091628", PhoneType.House), new PhoneNumber("01047071628", PhoneType.Cell)); Customer savedCustomer = customerRepository.save(customer); customerId = savedCustomer.getId(); }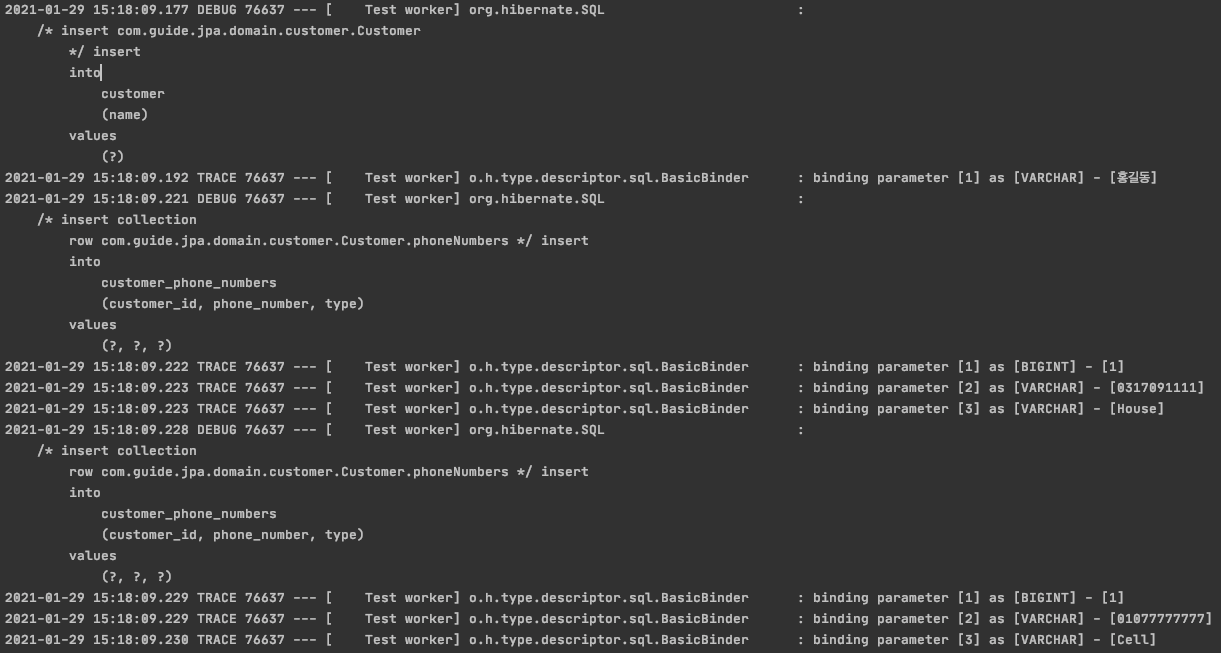
Customer 조회 시 실행되는 SQL을 살펴보겠습니다.
- customer 테이블에서 1회 조회
- Collection 필드를 참조하는부분을 주석처리해서 customer_phone_numbers 테이블을 조회 하는 부분이 없습니다.
@Test @Order(2) public void 고객검색() { customerRepository.findById(customerId).ifPresent(e -> { System.out.println("ID : " + e.getId()); System.out.println("Name : " + e.getName()); /* for (PhoneNumber phoneNumber : e.getPhoneNumbers()) { System.out.println(phoneNumber.getPhoneNumber()); } */ }); }
이번에는 주석을 풀어서 Collection 필드를 참조할 경우 실행되는 SQL을 살펴보겠습니다.
- customer 테이블에서 1회 조회
- customer_phone_numbers 테이블에서 1회 조회
- PhoneNumber의 필드 값을 참조할 때 Lazy 로딩에 의해서 PhoneNumber 값을 SELECT함
- OneToMany와 차이점
- PhoneNumber는 Customer 엔티티를 통해서만 조회 가능
- PhoneNumber만 삭제 불가능
@Test @Order(2) public void 고객검색() { customerRepository.findById(customerId).ifPresent(e -> { System.out.println("ID : " + e.getId()); System.out.println("Name : " + e.getName()); for (PhoneNumber phoneNumber : e.getPhoneNumbers()) { System.out.println(phoneNumber.getPhoneNumber()); } }); }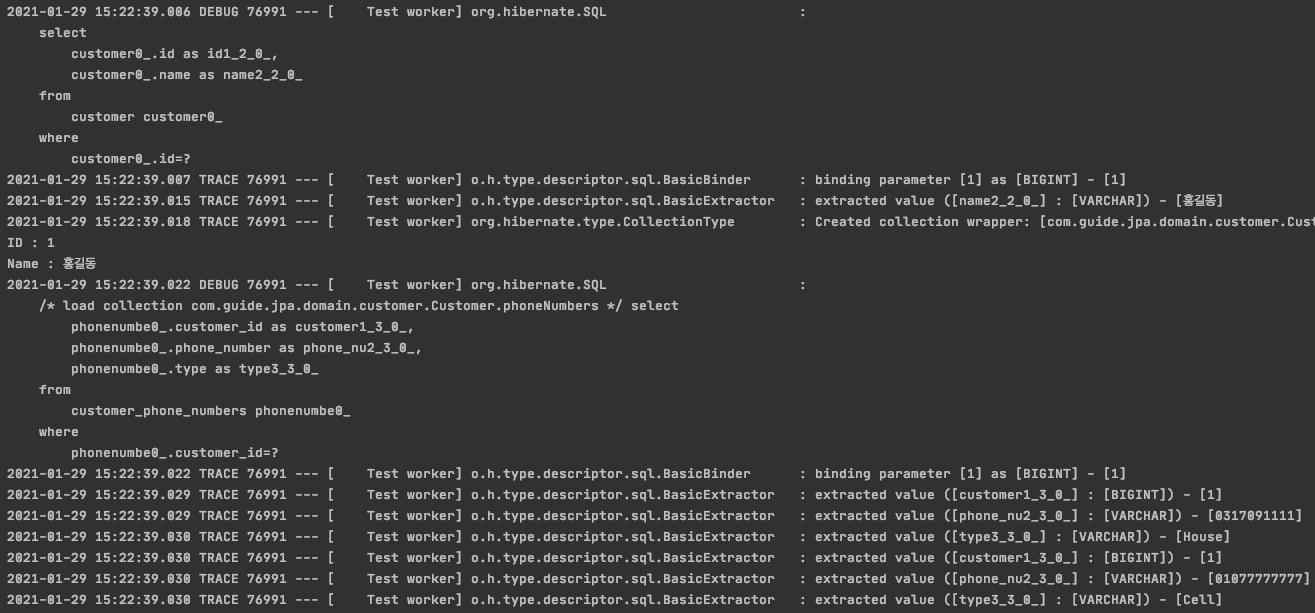
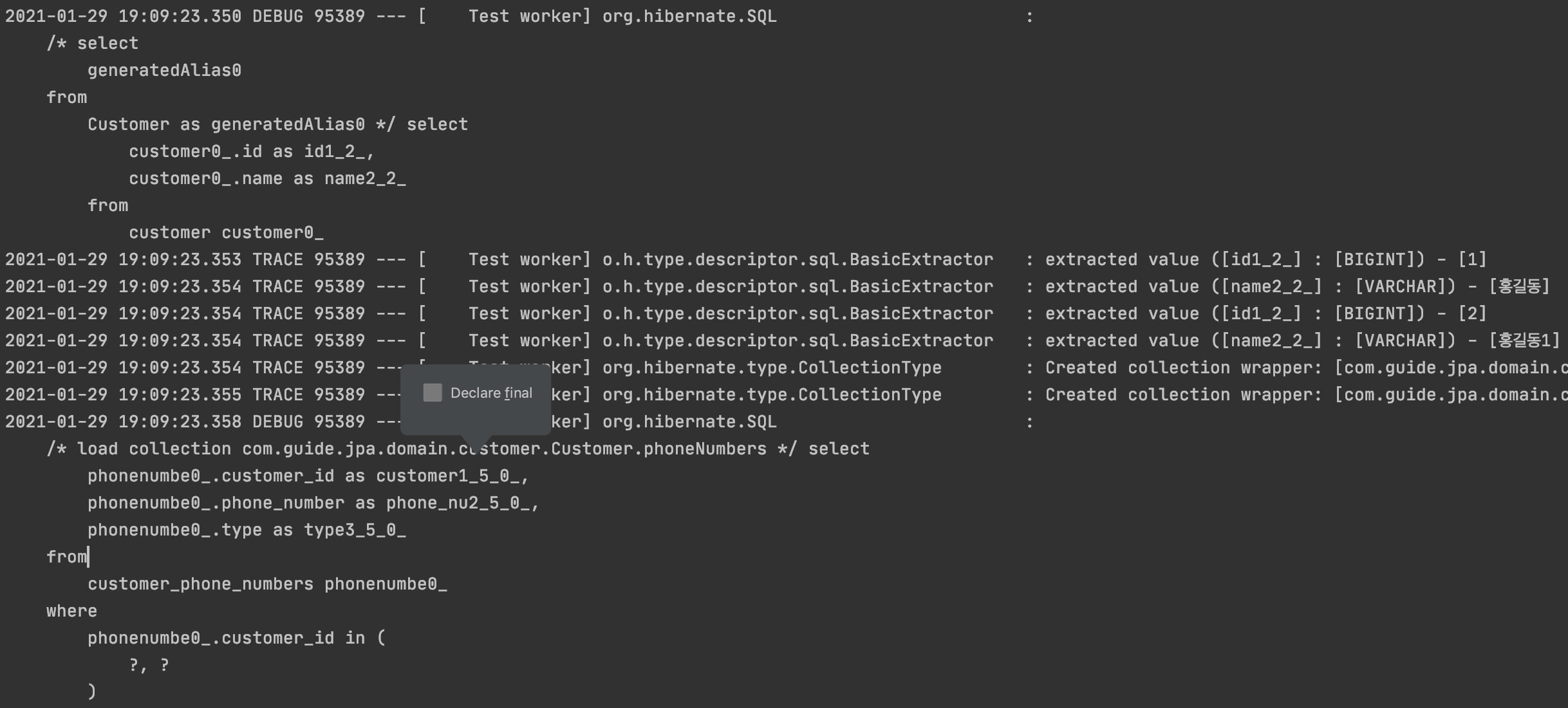
Customer를 2개 INSERT 한 후 전체 조회 시 SQL
- PhoneNumber 정보에 대해서 IN 절로 검색
Customer 삭제 시 실행되는 SQL
- customer 테이블에서 1회 삭제
- customer_phone_numbers 테이블에서 1회 삭제
@Test @Order(3) public void 고객삭제() { customerRepository.deleteById(customerId); }
'스프링프레임워크 > jpa' 카테고리의 다른 글
[JPA] ID 참조와 조인 테이블을 이용한 단방향 M:N 매핑 (0) 2021.01.14 [JPA] 영속성 컨텍스트 (1) 2021.01.13 [JPA] JPA 관련 유용한 블로그 글 모음 (0) 2021.01.12 [JPA] QueryDsl에서 Pageable 객체를 이용한 Sort 방법 (7) 2020.09.09